This article will explain how to build Hazelcast Embedded Cluster for distributed cache in Spring Boot application. Multiple instances of Spring Boot application will build Hazelcast local embedded cluster. Each instance is part of the cluster and cached objects will be synced across all cluster members.
Table of Contents
- Why Caching is Important?
- Hazelcast as Distributed Cache
- Hazelcast with Spring Boot
- Hazelcast Test Scenarios
- Conclusion
- Source Code
Why Caching is Important?
The majority of applications rely on retrieving data from databases to carry out their functions. Extracting data from a database is a resource-intensive process, as it involves the transmission of data over a network, ultimately affecting the performance of the application. This performance degradation becomes more pronounced as the frequency of database queries rises. A viable remedy is to store the data closer to the application, primarily in memory, to mitigate these issues.
When we cache data, we put it nearer to the application to avoid data transmission over the network. If your application has a considerable amount of static or rarely modifiable data, caching will significantly increase application performance.
Hazelcast as Distributed Cache
Hazelcast combines the RAM of all cluster members into a unified in-memory data store, creating a cache cluster that ensures faster access to cached data. This distributed architecture enhances data fault tolerance and scalability. In the event of a member’s failure, data is automatically redistributed among the remaining members.
In our example, we will run multiple instances of an application on a single system, each instance will be considered as a member of the cluster. It is also possible to build a cluster using multiple systems within a network.
Hazelcast supports two topologies for distributed cache:
- Embedded Cache Topology
- Client-Server Topology
We will use an Embedded Cache topology, in which both the application and the cached data reside on the same device. When a new entry is written to the cache, Hazelcast automatically handles that entry’s distribution to the other cluster members.
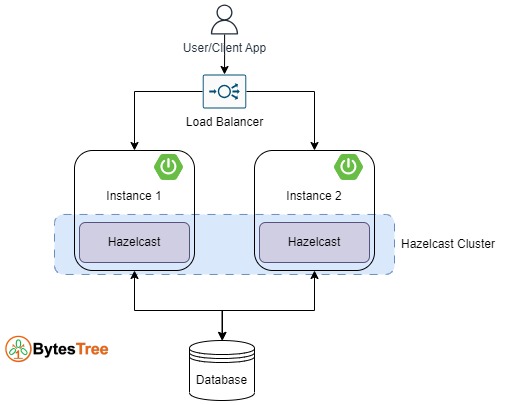
The above diagram shows the Hazelcast Cluster in the Spring Boot application with two members which we will be implementing. The production application should have a Load Balancer but in our example, we are sending the request directly to the individual application instance.
Hibernate Second Level Cache
Hazelcast with Spring Boot
Utilizing Hazelcast with Spring Boot requires only a few straightforward steps to follow. Add Hazelcast dependency, add Hazelcast configuration file, and use Cachable annotations.
We are going to build a Spring Boot application with the following features:
- REST APIs to add, retrieve, and delete product information
- Considering product information won’t change frequently but product retrieval requests are very often, we need to cache it to avoid multiple database calls
- Multiple instances of this application are running to handle the load
- Cached objects are available to all instances of cluster
- There should not be any impact if any instance goes down
Oh.. quite a lot of things to handle. But no worries it would not be that difficult. Let’s check all these steps in detail in our example application now.
First create a Spring Boot application exposing REST APIs to add, retrieve, and delete products. Write the Controller, Service, and Repository class. As our focus is on Hazelcast, the REST API code is not explained in detail here. You can refer to the complete source code at the end of this article.
Dependencies
To add Hazelcast caching support, the first thing to do is add the following dependencies in pom.xml.
<!--Caching dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
</dependency>Configuration
After adding Hazelcast dependencies, add the hazelcast configuration file hazelcast.yaml as follows:
hazelcast:
cluster-name: bytestree-hazelcast-cluster
map:
products:
max-idle-seconds: 3600
eviction:
eviction-policy: LRU
max-size-policy: PER_NODE
size: 300
network:
join:
multicast:
enabled: trueHere ‘products’ inside ‘map’ represents the name of the cache configuration to store products. You can add multiple cache configs if your application needs to cache different types of objects.
‘max-idle-seconds’ is the time in seconds after which any idle objects in the cache will be removed from the cache. The ‘eviction’ section configures the eviction conditions of cached objects. Adjust the ‘size’ as per your need, it will be the maximum number of objects that can be stored in the cache.
In the ‘network’ section we are enabling multicast which allows cluster members to find each other using multicast communication.
These are all basic configurations to build a local hazelcast cluster. Please refer to the Hazelcast documentation for more config parameters as per your use case.
We also have to enable caching for the application using @EnableCaching annotation.
@SpringBootApplication
@EnableCaching
public class HazelcastCacheApplication {
public static void main(String[] args) {
SpringApplication.run(HazelcastCacheApplication.class, args);
}
}Core Application
For simplicity, we will keep only three properties for our Product: id, name, and source. The ‘source’ attribute will tell us from which application instance/member the product information is saved. As we will run multiple application instances on different ports, we will store the port number in ‘source’ to identify the instance.
Note: The application code uses Spring JPA and it will create a ‘products’ table in the database if not exist. If your database already has a ‘products’ table, then change the table name in @Table annotation.
@Entity
@Table(name = "products")
public class Product implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private String source;
}The controller method of an API to save a product will set the ‘source’ attribute by getting the port of the running instance as follows:
@Autowired
Environment environment;
@PostMapping
public ResponseEntity<Product> saveProduct(@RequestBody Product product) {
String port = environment.getProperty("local.server.port");
product.setSource("Application@" + port);
Product savedProduct = productService.saveProduct(product);
return ResponseEntity.ok().body(savedProduct);
}Now look at the service class which uses @CachePut, @Cacheable, and @CacheEvict annotations to save, retrieve, and delete product objects from the cache. The value = “products“ attribute in each annotation represents the name of the cache. This should match the name of the cache configuration in hazelcast.yaml. The ‘key’ represents the attribute of the cached object used to identify the unique object within a cache. In our case, it’s the ‘id’ of the product.
@Override
@CachePut(value = "products", key = "#product.id")
public Product saveProduct(Product product) {
productRepository.save(product);
log.info("Adding Product: {}", product);
return product;
}
@Override
@CacheEvict(value = "products", key = "#id")
public void removeProduct(Integer id) {
productRepository.deleteById(id);
log.info("Removed Product with id: {}", id);
}
@Override
@Cacheable(value = "products", key = "#id")
public Product getProduct(Integer id) {
log.info("Getting Product with id {} from Repository", id);
Product product = productRepository.findById(id).orElse(null);
log.info("Product retrieved from Repository: {}", product);
return product;
}In the getProduct method, we added a few log statements. If the object is present in the cache, then we don’t have to use productRepository to get that from the database and this method will never execute the code within it. On the Get API call, if there are log statements of this method gets printed, then the object is returned from the database, else it is returned from the cache.
Running the application
Run two instances of the application in two command prompt windows from the directory of your project using the following commands. Make sure to use different ports in each instance.
For the first instance use port 8080:
mvn spring-boot:run -Dspring-boot.run.jvmArguments="-Dserver.port=8080"For the second instance use port 8081:
mvn spring-boot:run -Dspring-boot.run.jvmArguments="-Dserver.port=8081"You will see the formation of the Hazelcast cluster in the console as something like this:
Members {size:2, ver:2} [
Member [192.168.56.1]:5701 - 8038f861-0a7e-4627-b303-4fd37b6d0bb2
Member [192.168.56.1]:5702 - 5969e934-8dc6-4f74-93ff-e30b105e0493 this
]Test Scenarios
Now it is time to verify if our application meets the expectations.
One member can read data inserted by another without a database call
This should work because each instance is a member of the Hazelcast cluster and cached data is available to all members. To test that, add a new product by calling the POST API of the application in the new command prompt using cURL command:
curl -v --location "localhost:8080/product/" --header "Content-Type: application/json" --data "{\"name\": \"product1\"}"As you see above command we are calling the application instance running on port 8080 and passing JSON data to save a product with the name ‘product1’. You will get the saved product details in response as follows:
{"id":1,"name":"product1","source":"Application@8080"}The ‘source’ attribute holds the application port number 8080 because it is added by an instance running on port 8080.
Now try to get this product (with id 1) using a GET request from the instance running on port 8081 and check the console log.
curl --location "localhost:8081/product/1"In response you will get the product details and the console log of the 8081 instance will be something like this:
c.b.h.controller.ProductController: Product: Product(id=1, name=product1, source=Application@8080)The console has only Controller class logs and no logs of the Service class of method getProduct(). This proves that no database calls were made to get the product details because data is coming from the Hazelcast distributed cache cluster. Also, the object added in the cache by an instance running on 8080 is accessible by an instance running on 8081.
Until product 1 remains in the cache, there will not be any database calls on GET requests irrespective of the instance making the request. There will be a database call on the GET request If an object gets removed by idle time out or eviction conditions.
Delete operation will also remove the object from the cache in all members
To test this, add product 2 from instance at 8080, and delete it from instance 8081.
curl --location "localhost:8080/product/" --header "Content-Type: application/json" --data "{\"name\": \"product2\"}"
*** verify using GET call ***
curl --location "localhost:8081/product/2"
*** Delete using DELETE call ***
curl --location --request DELETE "localhost:8081/product/2"Now try to GET it from both instances. You will get a 404 status from both instances.
curl -v --location "localhost:8080/product/2"
curl -v --location "localhost:8081/product/2"
*** Response ***
< HTTP/1.1 404
< Content-Length: 0This proves that if an object is removed from the cache by one member, it will be removed from the entire cache cluster and no member holds the stale object.
Closing one member will not affect the cached data in the cluster
Add product 3 and product 4 on instances 8080 and 8081 respectively.
curl --location "localhost:8080/product/" --header "Content-Type: application/json" --data "{\"name\": \"product3\"}"
curl --location "localhost:8081/product/" --header "Content-Type: application/json" --data "{\"name\": \"product4\"}"Now shut down any one instance (say 8081) using the CTRL + C command and check if the other instance can get product 3 and product 4 without a database call.
curl --location "localhost:8080/product/3"
curl --location "localhost:8080/product/4"You should get the result and the console of the application will not have any logs for database calls. This proves that if any member of the cluster is down, it will not affect the cache.
Conclusion
- We have successfully built an application using Hazelcast distributed cache and Spring Boot.
- We built a Hazelcast local embedded cluster by running multiple instances of the application.
- We also verified that objects get cached when added and retrieval requests don’t need database calls until objects are present in the cache.
- The cache is shared and synced across members of the cluster.
- Closing one instance will not affect the cache.
Source Code
The complete source code is available at https://github.com/bytestree/hazelcast-cache-spring-boot